今年高考英语AI得分134,复旦武大校友这项研究有点意思
2022-06-25 13:07来源:IT之家
在挑战写语文作文之后,艾现在盯上了高考英语。
结果,好家伙,今年高考英语卷我考了134分。
这不是偶然的。
2018—2021年的10套真题测试中,AI的分数都在125以上,最高纪录138.5,听力和阅读理解也是满分。
这是由学者秦提出的,用于高考英语测试的人工智能系统。
它的参数只有GPT—3的十六分之一,但它的平均分比GPT—3高15分。
具体来说,就是对维基百科,YouTube等平台的信息进行重新提取和重构,然后喂给AI进行训练,从而使AI具有更强的泛化能力。
两位学者用100多页的论文深入解释了这一新范式。
那么,这个范式到底在说什么呢。
来深挖一下吧~
什么是重构前培训。
论文题目很简单,叫《重构的预训》。
核心观点一言以蔽之,简明扼要。注意数据!
笔者认为,世界上有价值的信息无处不在,目前的AI系统并没有充分利用数据中的信息。
比如维基百科和Github就包含了模型学习的各种信号:实体,关系,文本摘要,文本主题等由于技术瓶颈,以前没有考虑过这些信号
因此,本文提出了一种利用神经网络来存储和访问各种数据的方法。
它们以结构化的方式用信号来表示数据,这和数据科学中非常相似,我们经常把数据构造成表格或者JSON格式,然后通过一种特殊的语言来检索所需的信息。
具体来说,这里的信号其实是指数据中的有用信息。
比如莫扎特出生在萨尔茨堡这句话里,莫扎特和萨尔茨堡就是信号。
接下来利用提示法,可以把这些来自不同地方的信号统一成一种形式。
最后,这些重组的数据被集成并存储在语言模型中。
这样,研究可以统一来自10个数据源的26种不同类型的信号,使模型具有很强的泛化能力。
结果表明,在许多数据集上,RST—T和RST—A零样本学习的性能优于GPT—3。
为了进一步检验新方法的性能,笔者还想到了让AI做高考题的方法。
他们表示,现在很多工作方法都遵循中国GPT—3的思路,在评测应用场景上也遵循OpenAI和DeepMind。
比如胶水评测基准,蛋白质折叠评分等。
基于对目前AI模式发展的观察,笔者认为可以开辟一条新的赛道来尝试,于是想到了利用高考来培养AI手。
他们找来前几年共10套试卷做标记,请高中老师打分。
最后,开发了英语的人工智能模型,也可以称为秦。
从测试结果可以看出,秦绝对是一个学习高手,10套卷子的成绩都高于T0pp和3。
他们觉得现在的很多评测基准的任务都很单一,大部分都没有实用价值,很难和人的状况相比。
高考题目不仅涵盖了各种知识点,还直接有人类的分数进行对比,可谓一举两得。
NLP的第五范式。
P1。非神经网络时代的完全监督学习
P2。基于神经网络的全监督学习
P3。预培训,微调范例
P4。预训练,提示和预测范例
但基于目前对NLP发展的观察,他们认为也许未来可以用以数据为中心的方式来看待问题。
即预训/微调,少射/零射等概念的分化。会比较模糊,核心只会集中在一点上——
有多少有价值的信息,有多少可以利用。
此外,他们还提出了NLP进化的假说。
核心思想是技术发展的方向永远遵循这个——做得更少,实现更好更通用的系统。
复旦大学校友楼
本论文的第一部分是袁。
她毕业于武汉大学,获学士学位,后赴卡内基梅隆大学学习数据科学。
研究方向侧重于自然语言处理任务的文本生成和评测。
去年,她分别收到了AAAI 2022和NeurIPS 2021的论文,还获得了ACL 2021最佳演示论文奖。
2019年获复旦大学计算机系博士学位,师从邱希鹏教授和黄教授。
他的兴趣包括NLP模型的可解释性,迁移学习,基于任务的学习等。
博士期间拿了计算机领域的各种奖学金,包括IBM博士奖学金,微软奖学金,腾讯人工智能奖学金,百度奖学金。
还有一点
值得一提的是,当刘鹏飞向我们介绍这部作品时,他直言不讳地说,起初,我们并不打算提交它。
这是因为他们不希望会议论文的格式限制了构思论文的想象力。
我们决定把这篇论文作为一个故事来讲,给读者一种观影的体验。
这就是为什么我们在第三页设置了观看模式的全景。
就是带大家了解NLP发展的历史,以及我们对未来的期待,让每一个研究者都有一定的代入感,感受通过矿山寻宝引领前期训练语言模型走向美好明天的过程。
文末藏了一些惊喜彩蛋。
比如PLMs主题表情:
最后的插图是:
所以,一篇100多页的论文你不会看腻~
论文地址:
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
责任编辑:苏婉蓉
最新阅读
-
![百岁山与天津马拉松一起开跑,激发体育热爱]()
百岁山与天津马拉松一起开跑,激发体育热爱
逐梦天津,奔赴健康之旅,2023天津马拉松已于10月15日正式开跑。此次大赛全程42.195公里,设马拉松、半程马拉松、健康跑三个项目,共吸引了来自29个国家和地区,近9万人报名。其中年龄最大的选手出...
2023-10-15 22:03 -
![巨量引擎“抖「营」全收” 开启全渠道联合经营的新时代]()
巨量引擎“抖「营」全收” 开启全渠道联合经营的新时
企业对于实现确定性增长与ROI提升的诉求愈加强烈,全渠道增长成为越来越多的企业的关注焦点。如何帮助企业建立全局视角,为全局ROI提升和生意增长创造增量?近日,在第十六届金投赏国际创意节的“全域增长”论...
2023-10-11 18:13 -
-
![成绩单“耀眼”!中秋国庆武隆接待游客141.92万人次]()
成绩单“耀眼”!中秋国庆武隆接待游客141.92万
今年国庆期间,武隆旅游人气超旺,各景区景点节日氛围浓厚,市民、游客出游热情高涨。据统计,今年中秋国庆期间武隆共接待游客141.92万人次,实现综合旅游收入45650.82万元,较2022年同期分别增长...
2023-10-08 18:20 -
![家电市场迎“金九银十” 品质家电更受年轻消费者青睐]()
家电市场迎“金九银十” 品质家电更受年轻消费者青睐
“金九银十”是家电消费旺季。在一系列促消费政策助推下,家电厂商抢抓机遇深挖潜力,中秋国庆假期家电市场销售明显升温。2023年是被商务部确定的“消费提振年”,有关部门出台政策措施促进电子产品消费、家居消...
2023-10-08 14:36 -
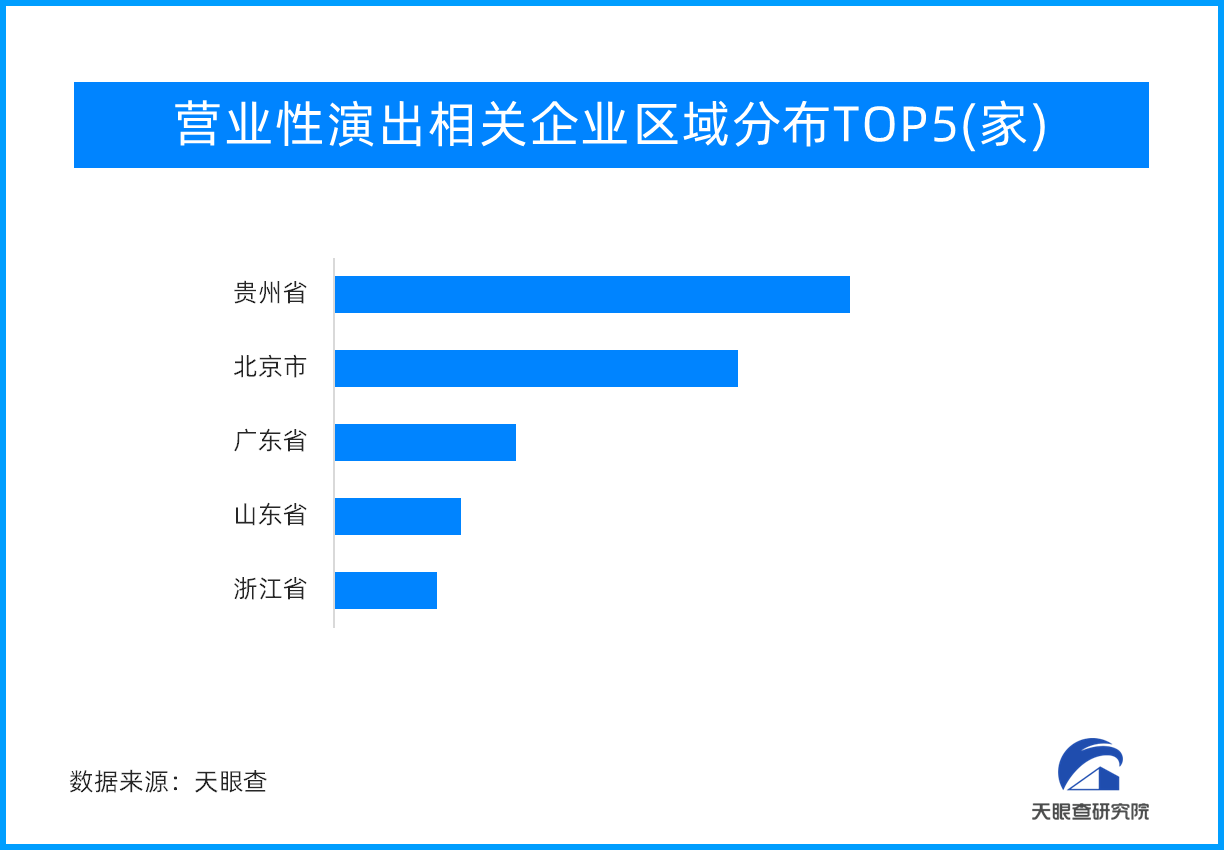
![旅游市场带“火”演艺市场 营业性演出超20亿元,同比增227.68%]()
旅游市场带“火”演艺市场 营业性演出超20亿元,同
近日,据中国演出行业协会监测数据显示,全国营业性演出44237场,与去年十一假期同比增227.68%,与2019年同比增长48.95%;票房收入20.05亿元,与去年同比增长322.14%,与2019...
2023-10-08 14:19 -
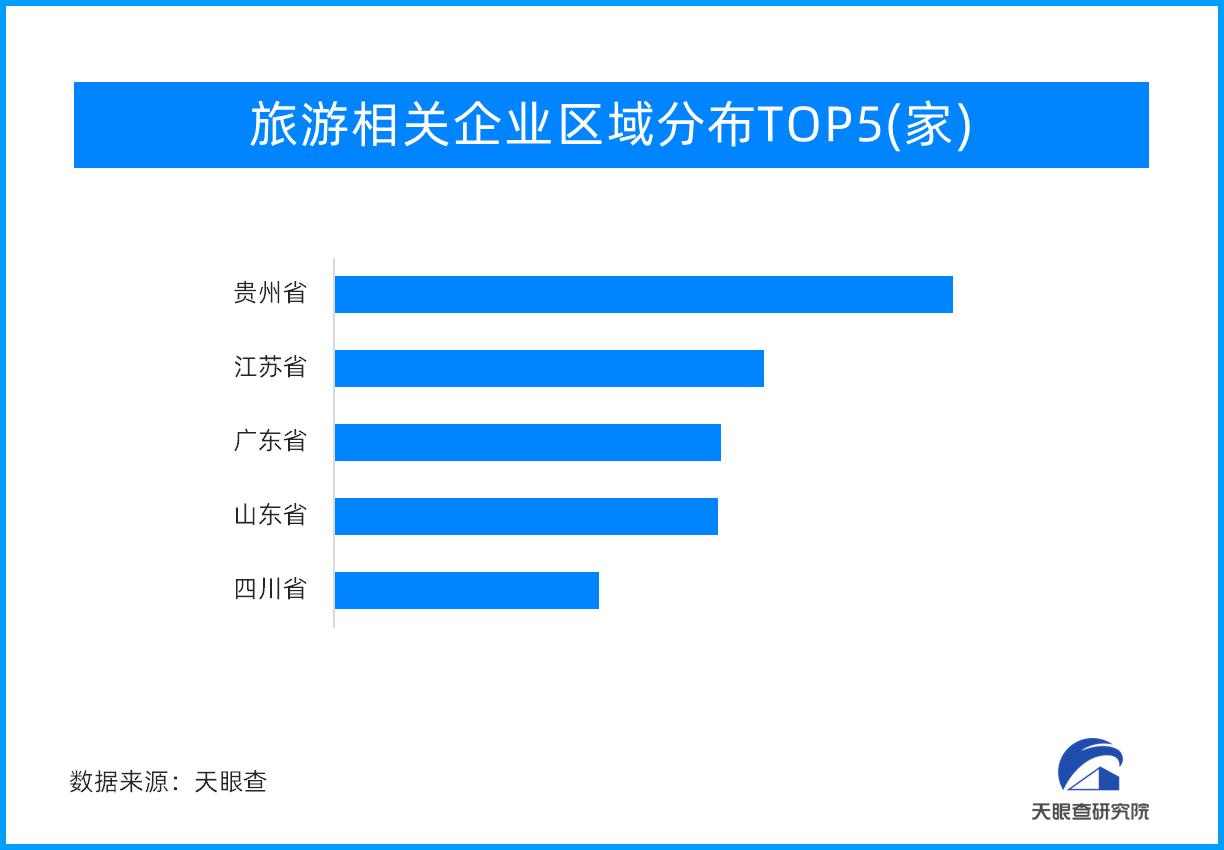
![旅游收入同比增长129.5%!中秋国庆“超级黄金周”再创佳绩]()
旅游收入同比增长129.5%!中秋国庆“超级黄金周
近日,文化和旅游部统计数据显示,2023年中秋节、国庆节假期,文化和旅游行业恢复势头强劲,全国假日市场平稳有序。经测算,国内旅游出游人数8.26亿人次,按可比口径同比增长71.3%,按可比口径较201...
2023-10-08 14:05 -
![数智赋能行业变革,见证企业超凡蜕变——爱采购明星企业大赛“了不起的改变”第二届郑州分会场成功举办]()
数智赋能行业变革,见证企业超凡蜕变——爱采购明星企
21世纪以来,科技领域迎来一轮轮颠覆性的变革——人工智能技术的次次迭代,信息化、智能化的汹涌浪潮,不断推动着中国制造企业持续向数智化阶段大步迈进,势不可挡。技术发展为各行各业持续积蓄着活力,有无数新兴...
2023-09-28 15:13 -
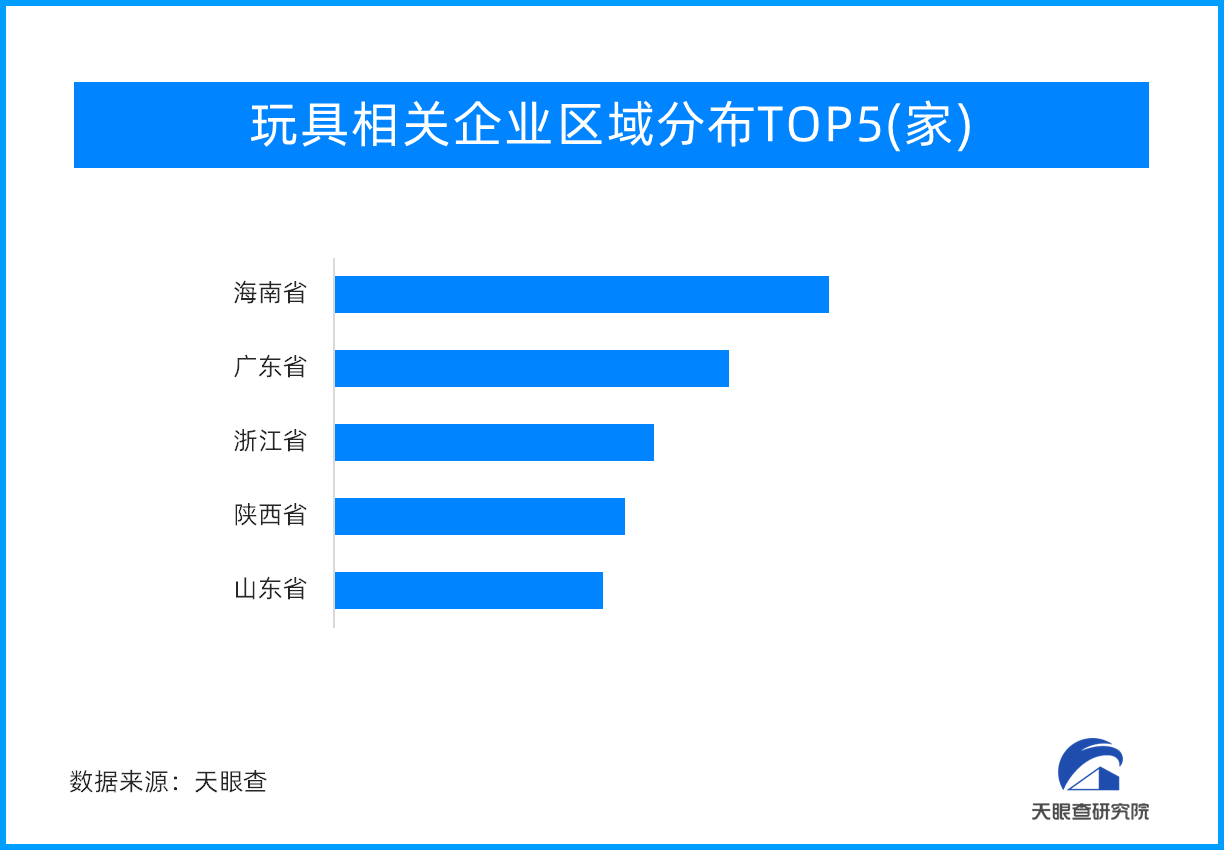
![天眼新知 — 益智玩具、毛绒玩具、潮流玩具…玩具市场迎多元化发展浪潮]()
天眼新知 — 益智玩具、毛绒玩具、潮流玩具…玩具市
玩具给儿童构建了一个美好的世界,不仅给孩子们带来快乐,同时给成年人启发,在残酷的生活中,让他们想起有关勇气、好奇心和对世界温柔相待。一、玩具产业:成长道路不可或缺的“玩伴”玩具产业是指以玩具产品为经营...
2023-09-27 17:41 -
![中国农资固始服务中心《农作物种植示范基地》举办首届现场观摩会]()
中国农资固始服务中心《农作物种植示范基地》举办首届
中国农民丰收节前夕,由中国农资固始服务中心举办的首届农作物种植示范基地现场观摩会,在河南省固始县洪埠乡倪岗村700亩示范田举行。据负责人杨跃柳介绍,此次举办的目的,是为贯彻中华全国供销总社第七届理事会...
2023-09-23 18:46